编码方法(北大青鸟11s汉字内码表)
Unicode字符集和UTF 8、UTF-16、UTF-32编码
原2021-09-11 11:46跟踪内存ASCII码
在早期的计算时期,ASCII码被用来表示字符。英语中只有26个字母和一些其他特殊的字符和符号。
下表是ASCII码的对照表,包括字符及其对应的十进制和十六进制值。
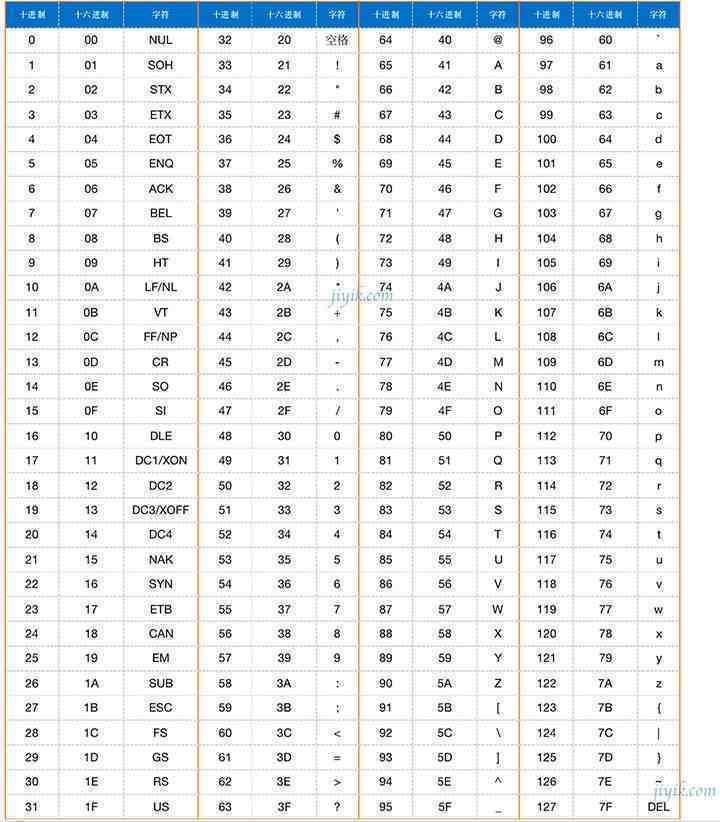 ASCII码对照表
ASCII码对照表
从上表可以推断,ASCII值在十进制中可以表示为0到127。让我们看看8位字节的0和127的二进制表示。
0显示为
 0的二进制表示
0的二进制表示
27表现为
 27二进制表示
27二进制表示
从上面的二进制表示可以推断,十进制值0到127可以用7位表示,第8位是空空的。
警告:从这个地方,混乱开始了。
人们想出了不同的方法来应用剩余的第八位数字,以便它可以表示从128到255的十进制值。于是冲突就产生了。比如越南人用十进制值182代表越南语字母,印度人用同样的值182代表印地语字母。因此,如果印度人写的电子邮件包含信件,并且被越南人查看,则该邮件将显示为。显然,这不是预期的结果。
那么如何解决这个问题呢?接下来,是Unicode出现的时候了。
Unicode和代码点
Unicode字符集将世界上的每个字符映射到一个唯一的数字。这确保了不同语言的字母之间没有冲突。这些数字与平台无关。
在unicode术语中,这些唯一的数字称为代码点。
我们来看看他们是怎么被引用的。
应用程序代码点指的是拉丁字符。
U+1E4D
U+代表unicode,1E4D是赋给字符的十六进制值。
英文字母A表示为U+0041。
好了,既然我知道了这些,现在是亮点的时候了。
UTF-8编码
现在我们知道了什么是unicode,以及如何将世界上的每个字母分配到一个唯一的代码点,我们需要一种方法在计算机内存中表示这些代码点。这就是字符编码发挥作用的地方。其中最著名的是UTF-8编码。
UTF-8编码技术资源网码是一种大小可变的编码方案,用于表示内存中的unicode码位。可变大小编码意味着码点应根据其大小用1、2、3或4个字节来表示。
UTF-8 1字节编码
一个字节代码表示第一位是0。
 UTF8 1字节编码表示方法
UTF8 1字节编码表示方法
英文字母a的unicode码位是U+0041。它的二进制表示是1000001。
UTF-8编码表示为
01000001
红色的0位表示应该应用1字节编码,其余的位表示代码点。
UTF 8双字节编码
代码点为U+00F1的拉丁字母的二进制值是11110001。该值大于可由1字节编码模式表示的最大值,因此UTF-8 2字节编码表示将应用于该字母表。
2字节编码方法由第一字节位中的高三位的位序列110和第二字节位中的高两位的位序列10来标识。
 2字节编码方法在UTF8技术资源网中的表达
2字节编码方法在UTF8技术资源网中的表达
Unicode码位U+00F1的二进制值是1111 0001。用2字节编码模式填充这些位,我们得到如下所示的UTF-8 2字节编码表示。
从映射到第二个字节的最低有效位的码位的最低有效位开始填充。
1100001110110001
蓝色二进制数11110001代表码位U+00F1的二进制值,红色为2字节编码标识符。黑色用于填充字节中的空位。
UTF 8 3字节编码
代码点为U+1E4D的拉丁字符应该用3字节编码表示,因为它大于2字节编码所能表示的最大值。
3字节代码由第一字节中的位序列1110和第二和第三字节中的位序列10来标识。
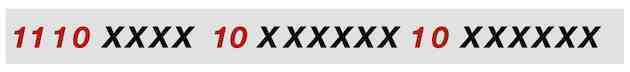 UTF8 3字节编码表示
UTF8 3字节编码表示
十六进制码位0x1E4D,对应的二进制值是1111001001101。通过将这些位填充到上述编码模式中,我们得到如下所示的UTF-8 3字节编码表示。
填充从映射到第三个字节的最低有效位的码位的最低有效位开始。
111000011011100110001101
红色位代表3字节代码,黑色位是填充位,蓝色位代表代码点。
UTF 8 4字节编码
表情U+1F62D的Unicode码位技术资源网。这大于3字节编码表示可应用的最大值,因此将应用4字节编码表示。
4字节代码由第一个字节的11110和随后的第二、第三和第四个字节的10来标识。
 UTF8 4字节编码表示
UTF8 4字节编码表示
U+1F62D的二进制表示是11111011000101101。通过将这些位填充到上述编码模式中,我们得到了UTF-8 4字节编码。代码的最低有效位映射到第四个字节的最低有效位,依此类推。