keras入门必看教程(如何快速入门Keras)
这一次,我们将谈论keras,一个简单而流行的深度学习框架,一个从训练到测试结果的图像分类义务的全过程。
相关的代码和数据都在我们的Git上。希望你能跟进这个Git项目,以后不断更新自己在不同框架下的义务。
https://github.com/longpeng2008/yousan.ai
1什么是Keras?
Keras是一个非常流行和简单的深度学习框架。它的设计参考了torch,用Python语言编写。它是一个高度模块化的神经网络库,支持GPU和CPU。可以在TensorFlow,CNTK或者Theano上运行。Keras的特点是可以快速建立模型,简单方便地将想法转化为实验验证,这是高效科学讨论的症结所在。
2个Keras安装配置
Keras的安装很简单,但是需要先安装一个后端框架作为支撑,比如TensorFlow,CNTK,Theano,但是官网强烈推荐TensorFlow作为Keras的后端。在这个例子中,TensorFlow版本1.4.0被用作Keras的后端进行测试。
sudo pip install tensorflow==1.4.0sudo pip install keras==2.1.4
通过以上两个命令,可以完成TensorFlow和Keras的安装。需要注意的是,Keras和TensorFlow的版本要对应,否则会出现意想不到的问题。具体版本对应可以在线查询。
3 Keras自定义数据
3.1 MNIST的例子
MNIST手写字符分类认为是“Hello Word!”在深度学习的框架下。,下面简单介绍一下MNIST数据集的测试情况。Keras官方github的示例目录提供了几个MNIST案例的代码。下载文件mnist_mlp.py和mnist_cnn.py并在本地运行。其他文件的读者也可以自己测试。
3.2数据定义
前面我们介绍了MNIST数据集的例子,很多读者在学习深度学习框架的时候卡在了这一步。运行MNIST实例后,他们对此无能为力。很大的原因可能是他们不知道如何处理自己的数据集。在本节中,我们将通过一个简单的图像分类案例来介绍如何实现自定义数据集。
数据处理有几种方法。一个是像MNIST和CIFAR这样的数据集。这些数据集的特点是为用户打包和封装了数据。用户load_data可以导入数据。其实就是提前对数据进行分析,然后保存在诸如。pkl或者。h5,然后在训练模型时直接导入到网络中。另一种是直接从本地读取文件,分析成网络的必要模式,输入网络进行训练。但实际情况是,对于某个项目,我们总是找不到对应的打包数据集,所以自己建立一个数据集是非常重要的。
Keras提供了一个图像数据的数据增强文件,我们可以通过调用这个文件来实现加载网络数据的效果。
这里,采用keras的处理模块中的ImageDataGenerator类来定义具有图像分类义务的数据集生成器:
train_data_dir = '../../../../datas/head/train/'validation_data_dir = '../../../../datas/head/val'# augmentation configuration we will use for trainingtrain_datagen = ImageDataGenerator( rescale=1. / 255, shear_range=0.2, zoom_range=0.2, horizontal_flip=True)# augmentation configuration use for testing only rescalingval_datagen = ImageDataGenerator(rescale=1. / 255)train_generator = train_datagen.flow_from_directory( train_data_dir, target_size=(48, 48), batch_size=16)val_generator = val_datagen.flow_from_directory( validation_data_dir, target_size=(48, 48), batch_size=16)
下面简单介绍一下上面的代码。请转到Git项目获取完整的代码。
Keras的处理模块提供了一个图像生成类ImagGenerator,可以实时增强数据。在这个类下,有一个函数flow_from_directory。顾名思义,这个功能就是从文件夹中获取技术资源网的图片数据。更多ImageGenerator的应用,请参考官方源代码。数据集的结构如下:
datas/train/left/*.jpgdatas/train/right/*.jpgdatas/val/left/*.jpgdatas/val/right/*.jpg
这里需要注意的是,我们现在做的是一个简短的图像分类的强制训练。如果要完成语义切分、目的检测等义务。,我们需要自定义一个类(继承ImageDataGenerator),具体实现可以查询相关代码参考。
4 Keras网络建设
Keras网络模型有两种情况,顺序模型和应用函数API的模型类模型。本教程的例子采用了一个简单的三层卷积,以及一个由两层全收敛和一个分类层组成的网络模型。由于函数式API更加灵活方便,因此采用以下函数式方法来构建模型,定义如下:
4.1功能API
def simpleconv3(input_shape=(48, 48, 3), classes=2): img_input = Input(shape=input_shape) bn_axis = 3 x = Conv2D(12, (3, 3), strides=(2, 2), padding='same', name='conv1')(img_input) x = BatchNormalization(axis=bn_axis, name='bn_conv1')(x) x = Activation('relu')(x) x = Conv2D(24, (3, 3), strides=(2, 2), padding='same', name='conv2')(x) x = BatchNormalization(axis=bn_axis, name='bn_conv2')(x) x = Activation('relu')(x) x = Conv2D(48, (3, 3), strides=(2, 2), padding='same', name='conv3')(x) x = BatchNormalization(axis=bn_axis, name='bn_conv3')(x) x = Activation('relu')(x) x = Flatten()(x) x = Dense(1200, activation='relu')(x) x = Dense(128, activation='relu')(x) x = Dense(classes, activation='softmax')(x) model = Model(img_input, x) return modelx = Conv2D(12, (3, 3), strides=(2, 2), padding='same', name='conv1')(img_input)
即输出为12通道,卷积核大小为3*3,步长为2,padding='same '表示边缘补零。
x = BatchNormalization(axis=bn_axis, name='bn_conv1')(x)
Axis表示要归一化的轴,bn_axis=3。因为采用TensorFlow作为后端,所以这个代码是用通道号的轴的归一化来表示的。
X = Flatten()(x)表示卷积特征图被拉伸到与全内聚层紧密相连()。
x = Dense(1200, activation='relu')(x)
Dense()实现全内聚层的功能,1200是输出维度,“‘relu’代表激活函数,可以通过其他函数修改。
最后一层采用“softmax”激活函数实现技术资源网络的分类效果。
返回最终模型,包括网络的输入和输出。
4.2模型编译
网络建成后,需要在网络训练前进行编制,包括学习方法、损失函数、评价量表等。这些参数分离可以从优化器、损耗和度量模块中导入。具体代码如下:
from keras.optimizers import SGDfrom keras.losses import binary_crossentropyfrom keras.metrics import binary_accuracyfrom keras.callbacks import TensorBoardtensorboard = TensorBoard(log_dir=('./logs'))callbacks = []callbacks.append(tensorboard)loss = binary_crossentropymetrics = [binary_accuracy]optimizer = SGD(lr=0.001, decay=1e-6, momentum=0.9)
回调模块包括TensorBoard、ModelCheckpoint、LearningRateScheduler等功能。分离可用于可视化模型、设置模型审查点和设置学习率策略。
5模型训练和测试
5.1模型培训
Keras模型训练过程非常简单,只需要一行代码和几个参数就可以设置。具体代码如下:
history = model.fit_generator( train_generator, steps_per_epoch=num_train_samples // batch_size, epochs=epochs, callbacks=callbacks, validation_data=val_generator, validation_steps=num_val_samples // batch_size)
首先,指定前面介绍的数据生成器train _ generatorSteps_per_epoch是历元周期数,是训练样本数除以batch_size得到的;Epochs整个数据集重复训练的次数。
Keras是高度封装的。在模型训练的过程中,我们看不到网络的预测结果和网络的逆向流动过程。我们只需要定义损失函数。实际上,网络定义中的模型输出将包括网络的输入和输出。
5.2培训过程的可视化
Keras可以使用tensorboard来可视化训练过程。执行以下命令后,您可以在阅读器中访问http://127.0.0.1:6006来检查结果。
Tensorboard - logdir日志文件路径(默认路径= '。/logs ' ')
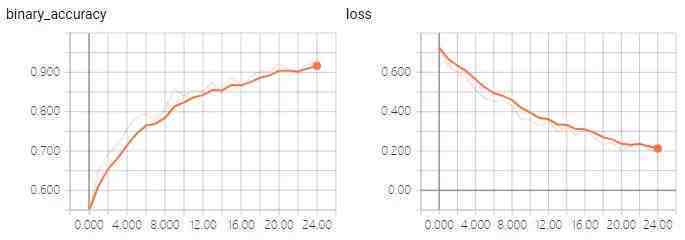
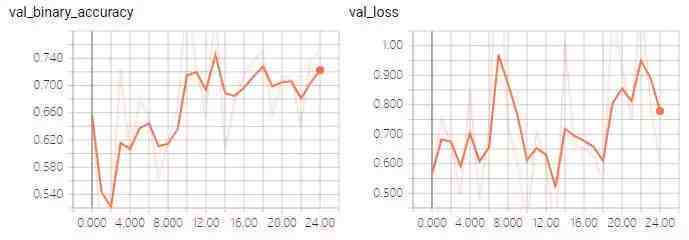
以上是分离损失和准确性的训练和测试过程。
5.3模型测试
model = simpleconv3()
model.load_weights(model_path,by_name=True)
image_path = '../../../../datas/head/train/0/1left.jpg '
img = Image.open(image_path)
img = img_to_array
Img = cv2.resize(img技术资源网,image_size)
img = np.expand_dims(img,axis=0)
img =预处理输入(img)
result = model.predict(img, batch_size=1)结果=模型.预测(img,batch_size=1)
打印(结果)
上面的代码简单介绍一下:模型测试的过程非常清晰。首先,加载模型,加载参数> >输入数据到网络> >模型预测。
6模型保留和导入
model = train_model(model, loss, metrics, optimizer, num_epochs)os.mkdir('models')model.save_weights('models/model.h5')
模型训练完成后,模型可以只保留一个代码model . save _ weights(' models/model . H5 ')。同样,模型的导入采用模型。load _ weights (model _ path,by_name=True)。需要注意的是,应该设置by _ name = true,这样才能保证与模型名相同的参数能够加载到模型中。当然,模型定义应该与参数相匹配。如果要进行微调,我们只需要保证新添加的网络层名称与预加载的模型参数名称不同即可。
7摘要
以上内容涵盖了采用keras进行分类义务的全过程,分别从数据导入、模型建立、模型训练、测试、模型保留、导入进行介绍。当然,这只是一些基础的应用,还有一些高级的、个性化的效果需要我们进一步学习。有机会的话,下次我们会介绍一些自定义网络层、设置check_point、特征可视化等功能。